Hochrangige Konzepte
Diese Dokumentation wurde automatisch übersetzt und kann Fehler enthalten. Zögern Sie nicht, einen Pull Request zu öffnen, um Änderungen vorzuschlagen.
LlamaIndex.TS hilft Ihnen beim Erstellen von LLM-basierten Anwendungen (z. B. Q&A, Chatbot) über benutzerdefinierte Daten.
In diesem Leitfaden zu den hochrangigen Konzepten erfahren Sie:
- wie ein LLM Fragen mithilfe Ihrer eigenen Daten beantworten kann.
- wichtige Konzepte und Module in LlamaIndex.TS zum Erstellen Ihrer eigenen Abfrage-Pipeline.
Beantwortung von Fragen über Ihre Daten
LlamaIndex verwendet eine zweistufige Methode, wenn Sie einen LLM mit Ihren Daten verwenden:
- Indexierungsstufe: Vorbereitung einer Wissensbasis und
- Abfragestufe: Abrufen relevanter Kontextinformationen aus dem Wissen, um dem LLM bei der Beantwortung einer Frage zu helfen.
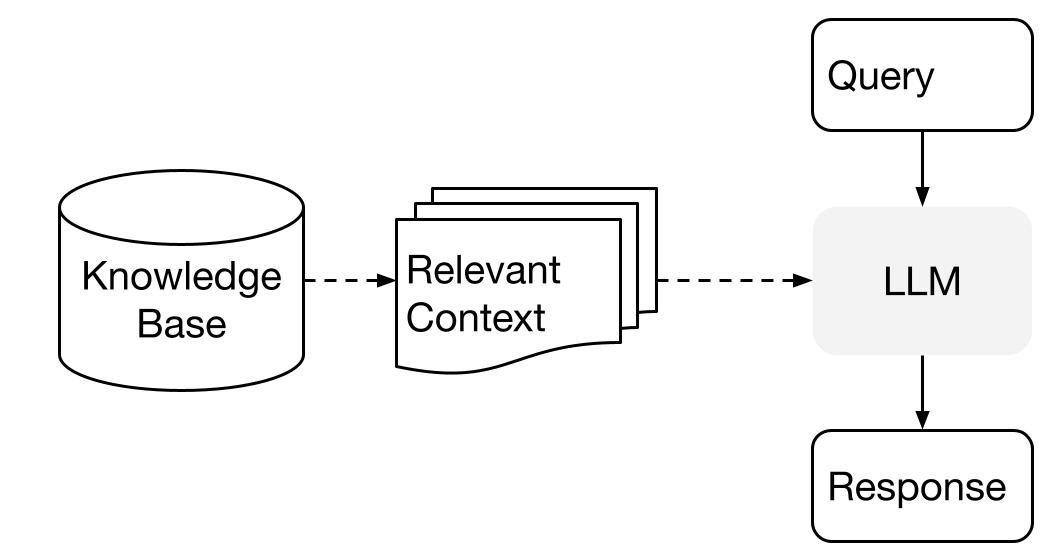
Dieser Prozess wird auch als Retrieval Augmented Generation (RAG) bezeichnet.
LlamaIndex.TS bietet das wesentliche Toolkit, um beide Schritte super einfach zu machen.
Lassen Sie uns jede Stufe im Detail erkunden.
Indexierungsphase
LlamaIndex.TS hilft Ihnen bei der Vorbereitung der Wissensbasis mit einer Reihe von Datenverbindern und Indizes.

Datenlader:
Ein Datenverbinder (d. h. Reader) nimmt Daten aus verschiedenen Datenquellen und Datenformaten auf und stellt sie in einer einfachen Document-Darstellung (Text und einfache Metadaten) bereit.
Dokumente / Knoten: Ein Document ist ein generischer Container für jede Datenquelle - zum Beispiel ein PDF, eine API-Ausgabe oder abgerufene Daten aus einer Datenbank. Ein Node ist die atomare Dateneinheit in LlamaIndex und repräsentiert einen "Chunk" eines Quelldokuments. Es handelt sich um eine umfassende Darstellung, die Metadaten und Beziehungen (zu anderen Knoten) enthält, um genaue und ausdrucksstarke Abrufoperationen zu ermöglichen.
Datenindizes: Nachdem Sie Ihre Daten aufgenommen haben, hilft Ihnen LlamaIndex dabei, die Daten in einem Format zu indizieren, das leicht abgerufen werden kann.
Unter der Haube analysiert LlamaIndex die Rohdokumente in Zwischenrepräsentationen, berechnet Vektor-Einbettungen und speichert Ihre Daten im Speicher oder auf der Festplatte.
"
Abfragestufe
In der Abfragestufe ruft die Abfrage-Pipeline den relevantesten Kontext ab, der einer Benutzerabfrage entspricht, und gibt diesen zusammen mit der Abfrage an den LLM weiter, um eine Antwort zu synthetisieren.
Dies gibt dem LLM aktuelles Wissen, das nicht in seinen ursprünglichen Trainingsdaten enthalten ist, (reduziert auch Halluzinationen).
Die Hauptherausforderung in der Abfragestufe besteht darin, Informationen aus (potenziell vielen) Wissensbasen abzurufen, zu orchestrieren und zu analysieren.
LlamaIndex bietet zusammensetzbare Module, die Ihnen beim Aufbau und Integrieren von RAG-Pipelines für Q&A (Abfrage-Engine), Chatbot (Chat-Engine) oder als Teil eines Agenten helfen.
Diese Bausteine können an individuelle Ranking-Präferenzen angepasst und strukturiert verwendet werden, um über mehrere Wissensbasen hinweg zu analysieren.
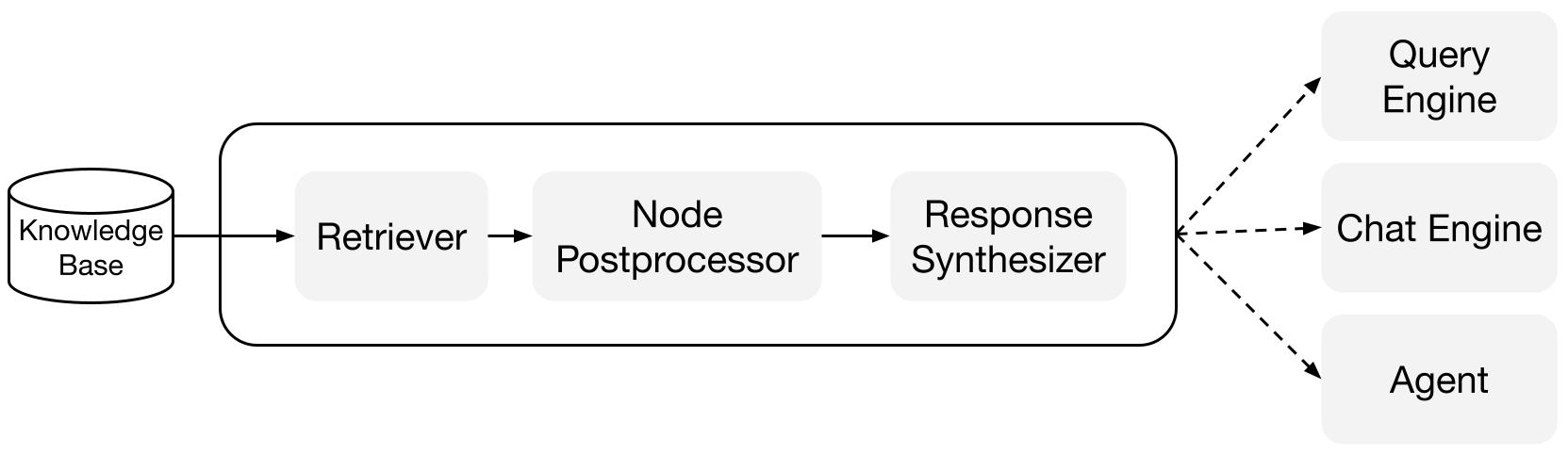
Bausteine
Retrievers: Ein Retriever definiert, wie relevanter Kontext effizient aus einer Wissensbasis (d. h. Index) abgerufen werden kann, wenn eine Abfrage vorliegt. Die spezifische Abruflogik unterscheidet sich je nach Index, wobei die beliebteste Methode ein dichter Abruf gegen einen Vektorindex ist.
Response Synthesizers: Ein Response Synthesizer generiert eine Antwort aus einem LLM, unter Verwendung einer Benutzerabfrage und einer gegebenen Menge abgerufener Textfragmente.
"
Pipelines
Abfrage-Engines: Eine Abfrage-Engine ist eine End-to-End-Pipeline, mit der Sie Fragen zu Ihren Daten stellen können. Sie nimmt eine natürliche Sprachabfrage entgegen und liefert eine Antwort sowie den abgerufenen Referenzkontext, der an den LLM weitergegeben wird.
Chat-Engines: Eine Chat-Engine ist eine End-to-End-Pipeline, um eine Konversation mit Ihren Daten zu führen (mehrere Hin und Her statt einer einzelnen Frage und Antwort).
"