แนวคิดระดับสูง
เอกสารนี้ได้รับการแปลโดยอัตโนมัติและอาจมีข้อผิดพลาด อย่าลังเลที่จะเปิด Pull Request เพื่อแนะนำการเปลี่ยนแปลง.
LlamaIndex.TS ช่วยให้คุณสร้างแอปพลิเคชันที่ใช้ LLM (เช่น Q&A, chatbot) บนข้อมูลที่กำหนดเองได้
ในเอกสารแนวคิดระดับสูงนี้ คุณจะเรียนรู้:
- วิธีการ LLM สามารถตอบคำถามโดยใช้ข้อมูลของคุณเองได้อย่างไร
- แนวคิดหลักและโมดูลใน LlamaIndex.TS ที่ใช้สร้าง query pipeline ของคุณเอง
การตอบคำถามทั่วข้อมูลของคุณ
LlamaIndex ใช้วิธีการสองขั้นตอนเมื่อใช้ LLM กับข้อมูลของคุณ:
- ขั้นตอนการสร้างดัชนี: เตรียมฐานความรู้
- ขั้นตอนการค้นหา: ดึงข้อมูลที่เกี่ยวข้องจากฐานความรู้เพื่อช่วย LLM ในการตอบคำถาม
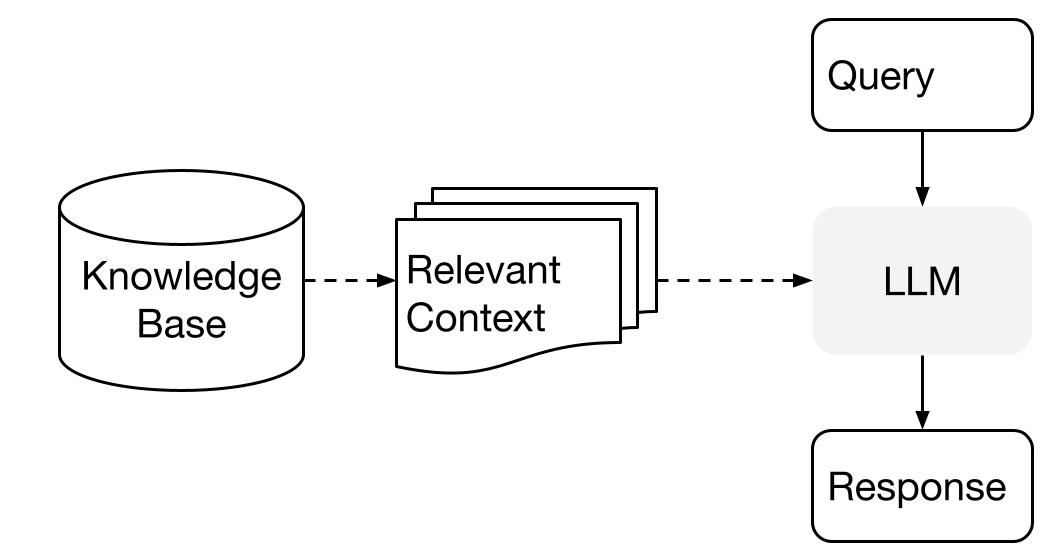
กระบวนการนี้เรียกว่า Retrieval Augmented Generation (RAG) ด้วย
LlamaIndex.TS มีเครื่องมือสำคัญที่ช่วยให้ทั้งสองขั้นตอนง่ายมาก
มาเรียนรู้เกี่ยวกับแต่ละขั้นตอนในรายละเอียด
ขั้นตอนการสร้างดัชนี
LlamaIndex.TS ช่วยให้คุณเตรียมฐานความรู้ด้วยชุดของตัวเชื่อมต่อข้อมูลและดัชนี

Data Loaders:
ตัวเชื่อมต่อข้อมูล (เช่น Reader) รับข้อมูลจากแหล่งข้อมูลและรูปแบบข้อมูลที่แตกต่างกันเข้าสู่รูปแบบ Document ที่เรียบง่าย (ข้อความและข้อมูลเบื้องต้น)
Documents / Nodes: Document เป็นคอนเทนเนอร์ทั่วไปที่ครอบคลุมแหล่งข้อมูลใด ๆ - เช่น PDF, ผลลัพธ์จาก API หรือข้อมูลที่ดึงมาจากฐานข้อมูล Node เป็นหน่วยข้อมูลอะตอมิกใน LlamaIndex และแทน "ชิ้น" ของ Document แห่งต้นฉบับ มันเป็นการแสดงผลที่หลากหลายที่รวมถึงข้อมูลเบื้องต้นและความสัมพันธ์ (กับโหนดอื่น ๆ) เพื่อให้สามารถดึงข้อมูลได้อย่างแม่นยำและสื่อความหมายได้
Data Indexes: เมื่อคุณได้รับข้อมูลเข้าสู่ระบบแล้ว LlamaIndex ช่วยคุณดัชนีข้อมูลให้อยู่ในรูปแบบที่ง่ายต่อการเรียกดู
ภายใน LlamaIndex จะแยกวิเคราะห์เอกสารเบื้องต้นเป็นรูปแบบกลาง คำนวณเวกเตอร์ซึ่งเป็นการแทนข้อมูลและจัดเก็บข้อมูลของคุณในหน่วยความจำหรือแผ่นดิสก์
"
ขั้นตอนการค้นหา
ในขั้นตอนการค้นหา pipeline ของคำถามจะดึงข้อมูลที่เกี่ยวข้องที่สุดตามคำถามของผู้ใช้ และส่งข้อมูลนั้นให้กับ LLM (พร้อมกับคำถาม) เพื่อสร้างคำตอบ
นี้จะทำให้ LLM มีความรู้ที่อัปเดตล่าสุดที่ไม่ได้อยู่ในข้อมูลการฝึกอบรมเดิมของมัน (ลดการเกิดภาพลวงตา)
ความท้าทายสำคัญในขั้นตอนการค้นหาคือการค้นหา การจัดการ และการแสดงเหตุผลเกี่ยวกับฐานความรู้ (ที่อาจมีหลายฐานความรู้)
LlamaIndex มีโมดูลที่สามารถสร้างและรวมเป็นระบบ RAG pipeline สำหรับ Q&A (query engine), chatbot (chat engine), หรือเป็นส่วนหนึ่งของตัวแทน
ส่วนประกอบเหล่านี้สามารถปรับแต่งให้สอดคล้องกับการจัดอันดับที่ต้องการ และสามารถรวมกันเพื่อแสดงเหตุผลเกี่ยวกับหลายฐานความรู้ในวิธีที่เป็นโครงสร้าง
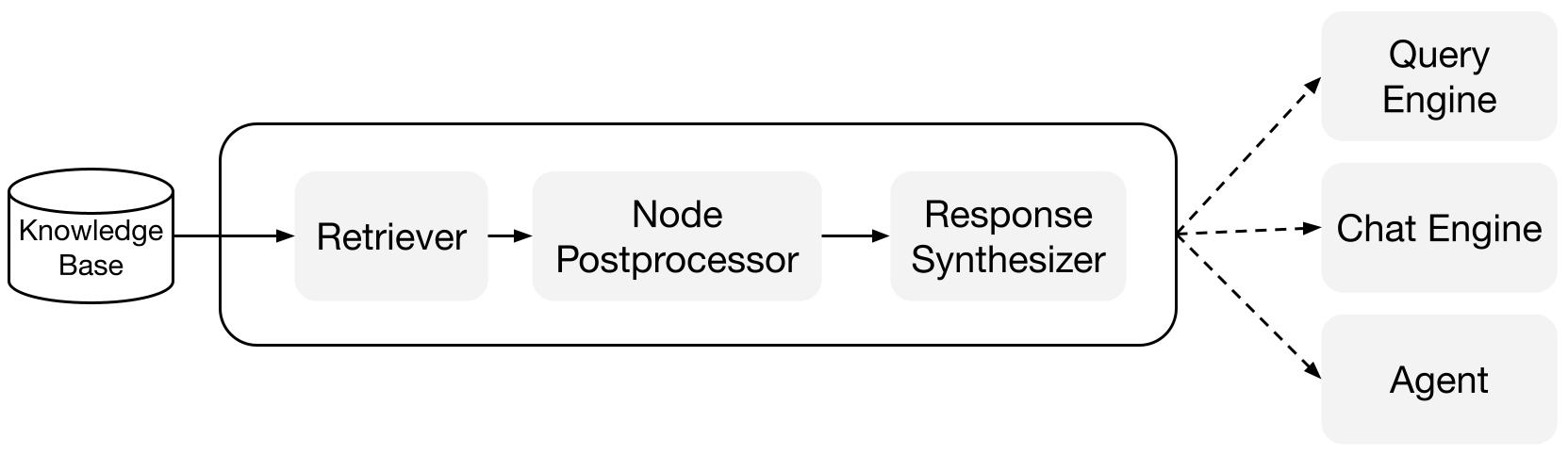
ส่วนประกอบพื้นฐาน
Retrievers: Retrievers กำหนดวิธีการค้นหาข้อมูลที่เกี่ยวข้องจากฐานความรู้ (เช่นดัชนี) อย่างมีประสิทธิภาพเมื่อมีคำถาม ตรรกะการค้นหาเฉพาะของแต่ละดัชนีแตกต่างกัน และดัชนีที่ได้รับความนิยมสูงสุดคือการค้นหาแบบหนาแน่นต่อดัชนีเวกเตอร์
Response Synthesizers: Response Synthesizers สร้างคำตอบจาก LLM โดยใช้คำถามของผู้ใช้และชุดข้อความที่ได้รับ
"
ท่องเที่ยว
Query Engines: Query engine เป็นท่องเที่ยวที่สามารถให้คุณถามคำถามเกี่ยวกับข้อมูลของคุณได้ มันรับคำถามเป็นภาษาธรรมชาติและส่งคำตอบพร้อมกับข้อมูลที่เกี่ยวข้องที่ดึงมาและส่งให้กับ LLM
Chat Engines: Chat engine เป็นท่องเที่ยวที่สามารถสร้างการสนทนากับข้อมูลของคุณได้ (มีการสื่อสารไปมาหลายครั้งแทนการถามคำถามและตอบคำถามเดียว)
"