高层次概念
LlamaIndex.TS 帮助您构建基于自定义数据的LLM(例如问答、聊天机器人)应用程序。
在这份高层次概念指南中,您将学习:
- LLM如何使用您自己的数据回答问题。
- LlamaIndex.TS中用于组合您自己的查询管道的关键概念和模块。
跨您的数据回答问题
LlamaIndex使用两阶段方法结合您的数据使用LLM:
- 索引阶段:准备知识库,
- 查询阶段:从知识中检索相关上下文以协助LLM回答问题
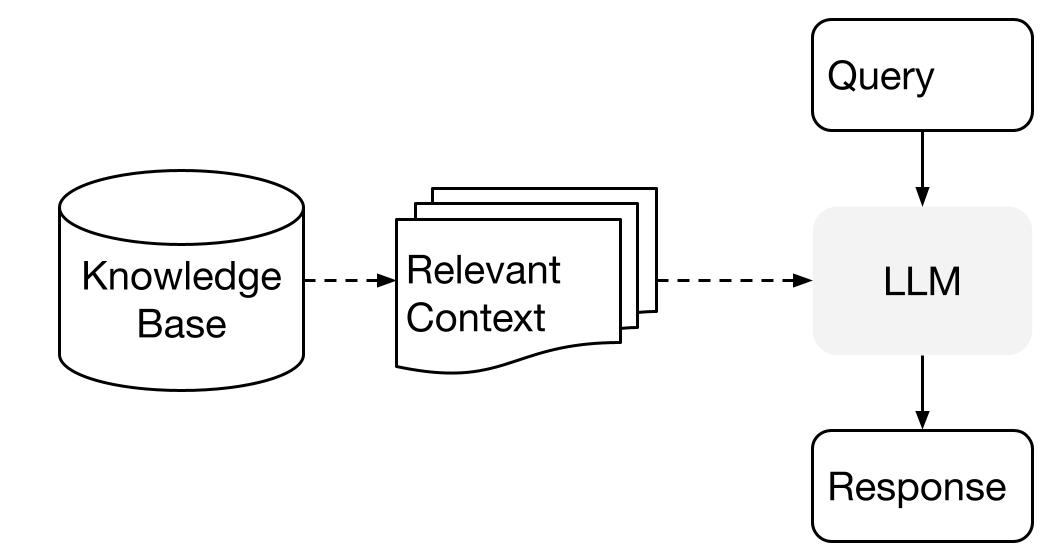
这个过程也被称为检索增强生成(Retrieval Augmented Generation,RAG)。
LlamaIndex.TS提供了必要的工具包,使这两个步骤变得非常简单。
让我们详细探索每个阶段。
索引阶段
LlamaIndex.TS 通过一系列数据连接器和索引帮助您准备知识库。

数据加载器:
数据连接器(即 Reader)从不同的数据源和数据格式摄取数据,转换成简单的 Document 表示(文本和简单元数据)。
文档 / 节点: Document 是围绕任何数据源的通用容器 - 例如,PDF、API 输出,或从数据库检索的数据。Node 是 LlamaIndex 中数据的原子单位,代表源 Document 的一个“块”。它是一个丰富的表示,包括元数据和关系(与其他节点),以实现准确和表达性的检索操作。
数据索引: 一旦您摄取了数据,LlamaIndex 将帮助您将数据索引成易于检索的格式。
在底层,LlamaIndex 解析原始文档为中间表示,计算向量嵌入,并将您的数据存储在内存或磁盘上。
查询阶段
在查询阶段,查询管道检索给定用户查询的最相关上下文, 并将其(连同查询)传递给LLM以合成响应。
这为LLM提供了最新的知识,这些知识不在其原始训练数据中, (同时减少幻觉现象)。
查询阶段的关键挑战是检索、协调和推理(可能很多)知识库。
LlamaIndex提供了可组合的模块,帮助您构建和集成RAG管道,用于问答(查询引擎 Query Engine),聊天机器人(聊天引擎 Chat Engine),或作为代理的一部分。
这些构建块可以定制以反映排名偏好,也可以组合以结构化地推理多个知识库。
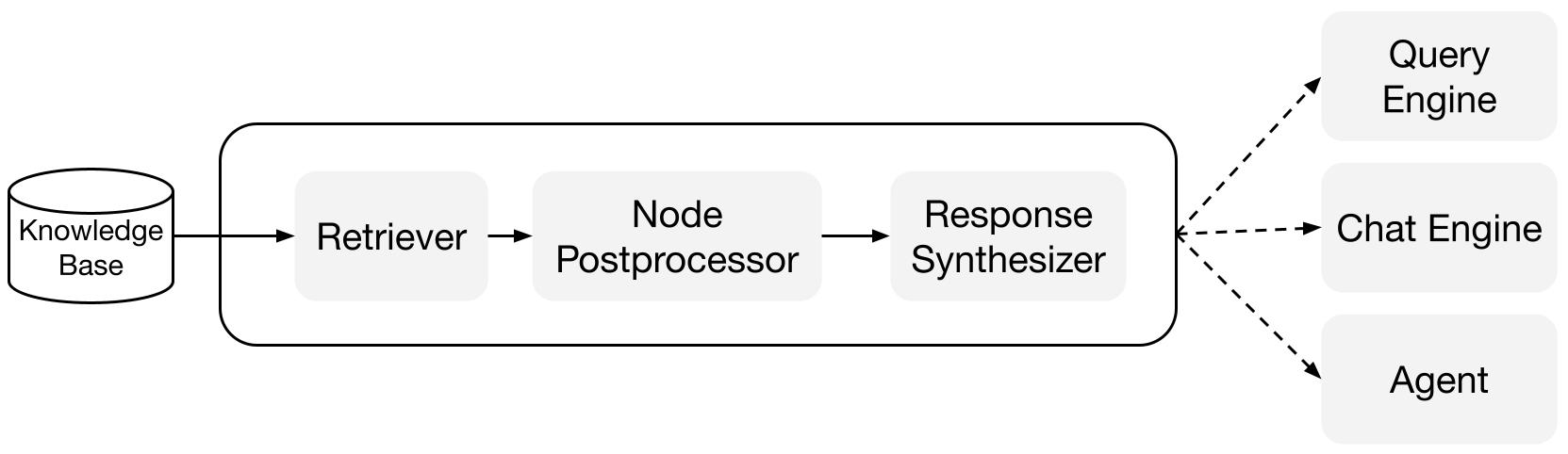
构建模块
检索器: 检索器定义了如何在给定查询时从知识库(即索引)中高效检索相关上下文。 具体的检索逻辑对于不同的索引有所不同,最流行的是对向量索引进行密集检索。
响应合成器: 响应合成器使用用户查询和一组给定的检索文本块,从LLM生成响应。
管道
查询引擎: 查询引擎是一个端到端的管道,允许您通过数据提出问题。 它接收自然语言查询,并返回响应,连同检索到的参考上下文一起传递给LLM。
聊天引擎: 聊天引擎是一个端到端的管道,用于与您的数据进行对话 (多次来回而不是单个问题和答案)。