Khái niệm cấp cao
Tài liệu này đã được dịch tự động và có thể chứa lỗi. Đừng ngần ngại mở một Pull Request để đề xuất thay đổi.
LlamaIndex.TS giúp bạn xây dựng các ứng dụng được cung cấp bởi LLM (ví dụ: Q&A, chatbot) trên dữ liệu tùy chỉnh.
Trong hướng dẫn về khái niệm cấp cao này, bạn sẽ tìm hiểu về:
- cách một LLM có thể trả lời câu hỏi bằng cách sử dụng dữ liệu của riêng bạn.
- các khái niệm và mô-đun chính trong LlamaIndex.TS để xây dựng pipeline truy vấn của riêng bạn.
Trả lời câu hỏi trên dữ liệu của bạn
LlamaIndex sử dụng một phương pháp hai giai đoạn khi sử dụng LLM với dữ liệu của bạn:
- giai đoạn lập chỉ mục: chuẩn bị một cơ sở kiến thức, và
- giai đoạn truy vấn: truy xuất ngữ cảnh liên quan từ kiến thức để hỗ trợ LLM trong việc đáp ứng câu hỏi
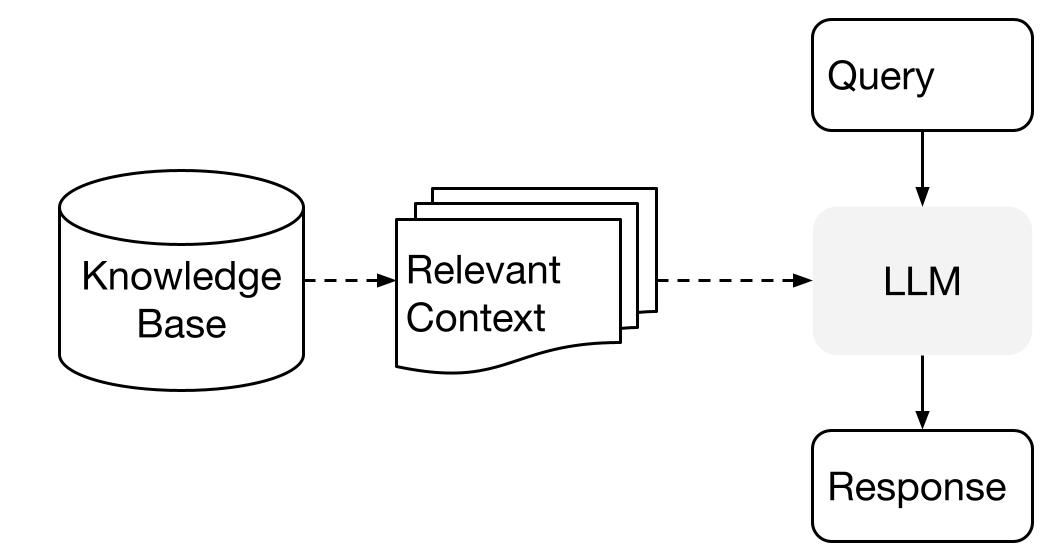
Quá trình này còn được gọi là Retrieval Augmented Generation (RAG).
LlamaIndex.TS cung cấp bộ công cụ cần thiết để làm cho cả hai giai đoạn này trở nên dễ dàng.
Hãy khám phá từng giai đoạn chi tiết.
Giai đoạn lập chỉ mục
LlamaIndex.TS giúp bạn chuẩn bị cơ sở kiến thức với một bộ kết nối dữ liệu và chỉ mục.

Data Loaders:
Một bộ kết nối dữ liệu (ví dụ: Reader) tiếp nhận dữ liệu từ các nguồn và định dạng dữ liệu khác nhau vào một biểu diễn Document đơn giản (văn bản và siêu dữ liệu đơn giản).
Documents / Nodes: Một Document là một container chung cho bất kỳ nguồn dữ liệu nào - ví dụ: một tệp PDF, đầu ra từ API hoặc dữ liệu được truy xuất từ cơ sở dữ liệu. Một Node là đơn vị nguyên tử của dữ liệu trong LlamaIndex và đại diện cho một "đoạn" của một Document nguồn. Đây là một biểu diễn phong phú bao gồm siêu dữ liệu và mối quan hệ (với các node khác) để cho phép các hoạt động truy xuất chính xác và diễn đạt.
Data Indexes: Sau khi bạn đã tiếp nhận dữ liệu của mình, LlamaIndex giúp bạn lập chỉ mục dữ liệu vào một định dạng dễ truy xuất.
Dưới nền tảng, LlamaIndex phân tích các tài liệu gốc thành các biểu diễn trung gian, tính toán vector nhúng và lưu trữ dữ liệu của bạn trong bộ nhớ hoặc đĩa.
"
Giai đoạn truy vấn
Trong giai đoạn truy vấn, pipeline truy vấn truy xuất ngữ cảnh phù hợp nhất dựa trên truy vấn của người dùng, và chuyển nó cho LLM (cùng với truy vấn) để tổng hợp một câu trả lời.
Điều này cung cấp cho LLM kiến thức cập nhật mà không có trong dữ liệu huấn luyện ban đầu của nó, (cũng giảm thiểu hiện tượng tưởng tượng).
Thách thức chính trong giai đoạn truy vấn là truy xuất, điều phối và lập luận qua (có thể là nhiều) cơ sở kiến thức.
LlamaIndex cung cấp các mô-đun có thể kết hợp giúp bạn xây dựng và tích hợp các pipeline RAG cho Q&A (query engine), chatbot (chat engine), hoặc là một phần của một agent.
Những khối xây dựng này có thể được tùy chỉnh để phản ánh sự ưu tiên xếp hạng, cũng như được tổ hợp để lập luận qua nhiều cơ sở kiến thức theo cách có cấu trúc.
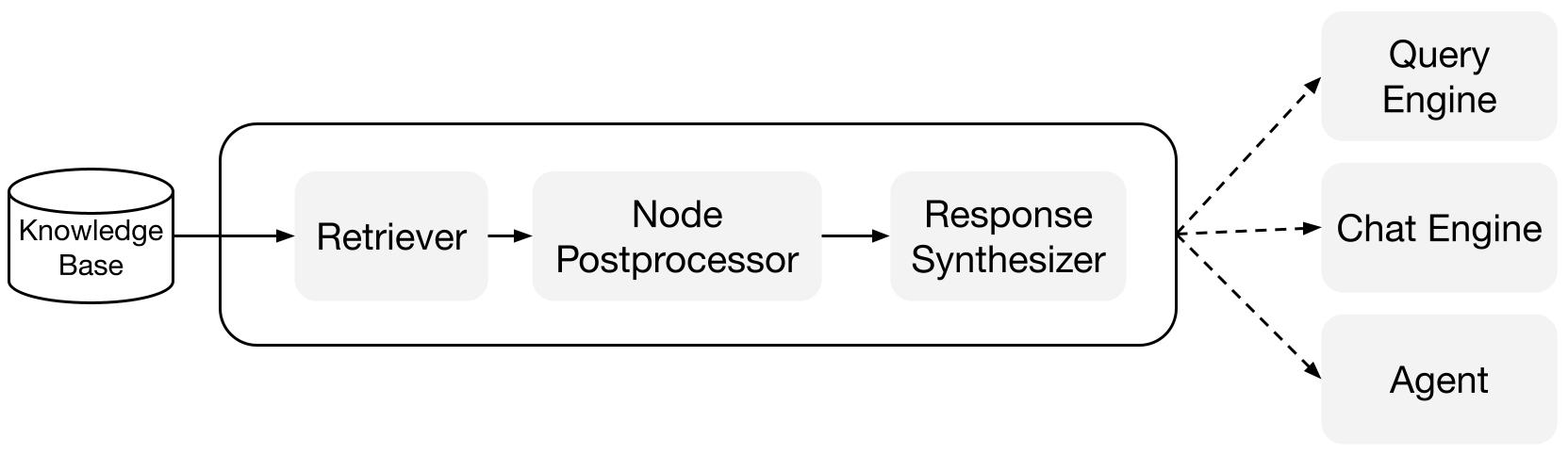
Các khối xây dựng
Retrievers: Một retriever xác định cách truy xuất ngữ cảnh phù hợp từ một cơ sở kiến thức (tức là chỉ mục) khi có một truy vấn. Logic truy xuất cụ thể khác nhau cho các chỉ mục khác nhau, phổ biến nhất là truy xuất dày đặc đối với một chỉ mục vector.
Response Synthesizers: Một response synthesizer tạo ra một câu trả lời từ một LLM, sử dụng truy vấn của người dùng và một tập hợp các đoạn văn bản đã được truy xuất.
"
Các pipeline
Query Engines: Một query engine là một pipeline end-to-end cho phép bạn đặt câu hỏi trên dữ liệu của bạn. Nó nhận vào một truy vấn bằng ngôn ngữ tự nhiên và trả về một câu trả lời, cùng với ngữ cảnh tham chiếu được truy xuất và chuyển cho LLM.
Chat Engines: Một chat engine là một pipeline end-to-end để có cuộc trò chuyện với dữ liệu của bạn (nhiều lần trao đổi thay vì chỉ một câu hỏi và câu trả lời duy nhất).
"