ハイレベルな概念
このドキュメントは自動的に翻訳されており、誤りを含んでいる可能性があります。変更を提案するためにプルリクエストを開くことを躊躇しないでください。
LlamaIndex.TSは、カスタムデータ上でLLMパワードアプリケーション(例:Q&A、チャットボット)を構築するのに役立ちます。
このハイレベルな概念ガイドでは、次のことを学びます:
- LLMが独自のデータを使用して質問に答える方法
- LlamaIndex.TSの主要な概念とモジュールを使用して、独自のクエリパイプラインを構築する方法
データ全体での質問への回答
LlamaIndexは、データとLLMを使用する場合に、2つのステージの方法を使用します:
- インデックス作成ステージ:ナレッジベースの準備
- クエリステージ:質問に応答するために、ナレッジから関連するコンテキストを取得する
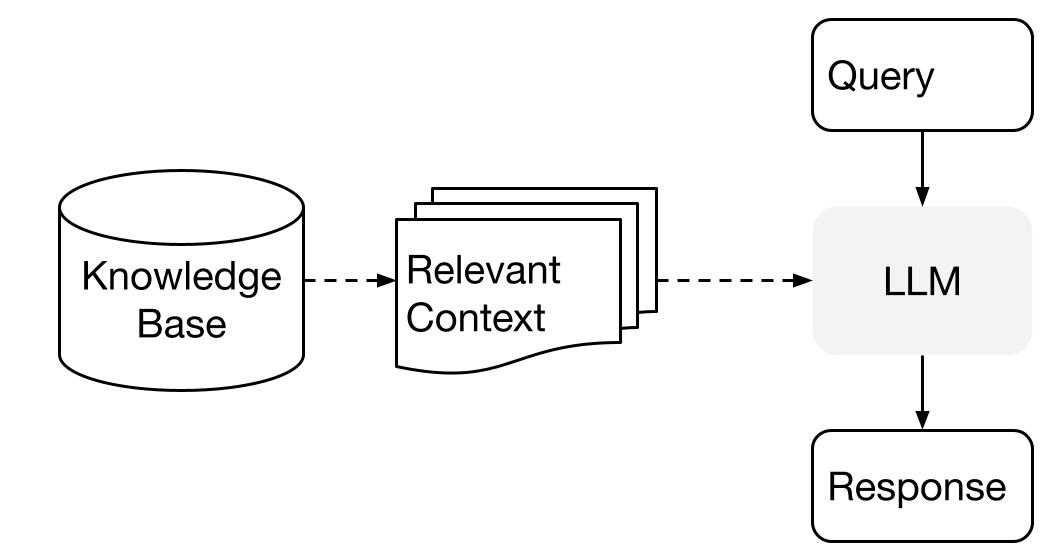
このプロセスは、Retrieval Augmented Generation(RAG)とも呼ばれています。
LlamaIndex.TSは、両方のステップを非常に簡単に行うための必須のツールキットを提供します。
それでは、各ステージを詳しく見てみましょう。
インデックス作成ステージ
LlamaIndex.TSは、データコネクタとインデックスのスイートを使用して、ナレッジベースを準備するのに役立ちます。

データローダー:
データコネクタ(つまり、Reader)は、さまざまなデータソースとデータ形式からデータを取り込み、シンプルなDocument表現(テキストとシンプルなメタデータ)に変換します。
ドキュメント/ノード:Documentは、任意のデータソース(例:PDF、APIの出力、データベースからの取得データ)を囲む汎用のコンテナです。Nodeは、LlamaIndexのデータの原子単位であり、ソースDocumentの「チャンク」を表します。これは、メタデータや関係(他のノードへの関連)を含む豊富な表現であり、正確で表現力のある検索操作を可能にします。
データインデックス: データを取り込んだ後、LlamaIndexはデータを簡単に取得できる形式にインデックス化するのに役立ちます。
LlamaIndexは、生のドキュメントを中間表現に解析し、ベクトル埋め込みを計算し、データをメモリ上またはディスク上に格納します。
クエリステージ
クエリパイプラインでは、ユーザーのクエリに基づいて最も関連性の高いコンテキストを取得し、それをLLMに渡して応答を合成します。
これにより、LLMは元のトレーニングデータにない最新の知識を得ることができます(幻覚も減少します)。
クエリステージの主な課題は、(潜在的に多数の)ナレッジベースに対して検索、オーケストレーション、および推論を行うことです。
LlamaIndexは、Q&A(クエリエンジン)、チャットボット(チャットエンジン)、またはエージェントの一部として使用するためのRAGパイプラインを構築および統合するのに役立つ組み合わせ可能なモジュールを提供します。
これらのビルディングブロックは、ランキングの優先順位を反映させるためにカスタマイズすることもでき、構造化された方法で複数のナレッジベースに対して推論を行うために組み合わせることもできます。
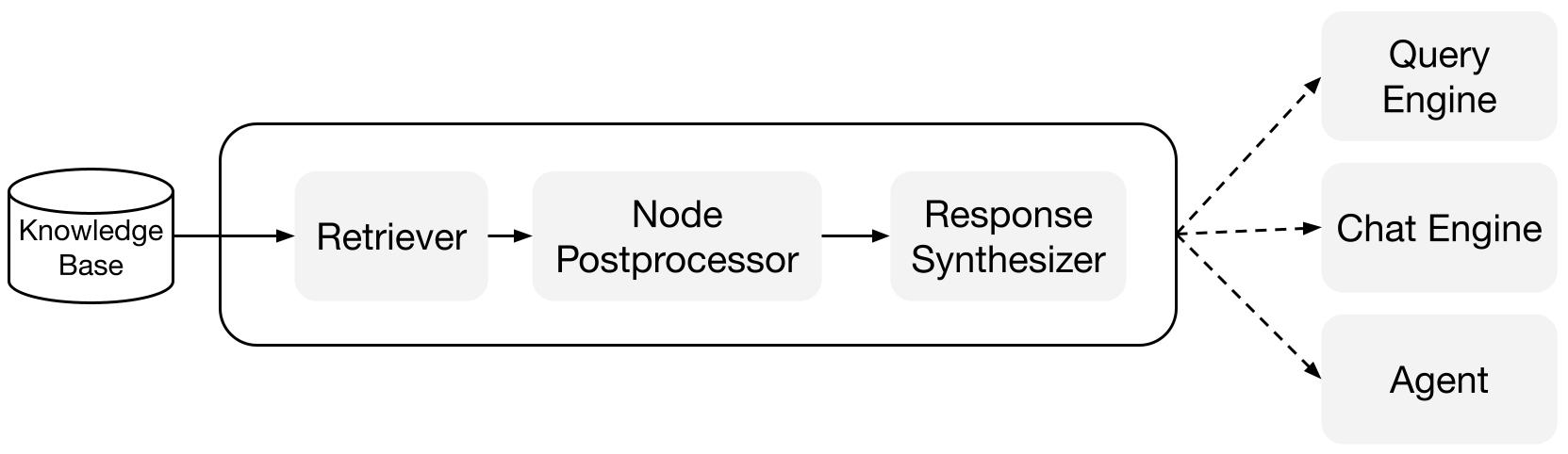
ビルディングブロック
Retrievers(リトリーバー): リトリーバーは、クエリが与えられたときにナレッジベース(つまりインデックス)から関連するコンテキストを効率的に取得する方法を定義します。 具体的な検索ロジックは、異なるインデックスによって異なりますが、最も一般的なのはベクトルインデックスに対する密な検索です。
Response Synthesizers(レスポンスシンセサイザー): レスポンスシンセサイザーは、LLMからの応答を生成するために、ユーザークエリと取得したテキストチャンクのセットを使用します。
パイプライン
クエリエンジン: クエリエンジンは、データに対して質問をするためのエンドツーエンドのパイプラインです。 自然言語のクエリを受け取り、応答とともにLLMに渡された参照コンテキストを返します。
チャットエンジン: チャットエンジンは、単一の質問と回答ではなく、データとの対話を行うためのエンドツーエンドのパイプラインです。
"