Concetti di alto livello
Questa documentazione è stata tradotta automaticamente e può contenere errori. Non esitare ad aprire una Pull Request per suggerire modifiche.
LlamaIndex.TS ti aiuta a costruire applicazioni basate su LLM (ad esempio, Q&A, chatbot) su dati personalizzati.
In questa guida ai concetti di alto livello, imparerai:
- come un LLM può rispondere alle domande utilizzando i tuoi dati.
- concetti chiave e moduli in LlamaIndex.TS per comporre la tua pipeline di interrogazione.
Rispondere alle domande sui tuoi dati
LlamaIndex utilizza un metodo a due fasi quando si utilizza un LLM con i tuoi dati:
- fase di indicizzazione: preparazione di una base di conoscenza, e
- fase di interrogazione: recupero del contesto rilevante dalla conoscenza per assistere il LLM nel rispondere a una domanda
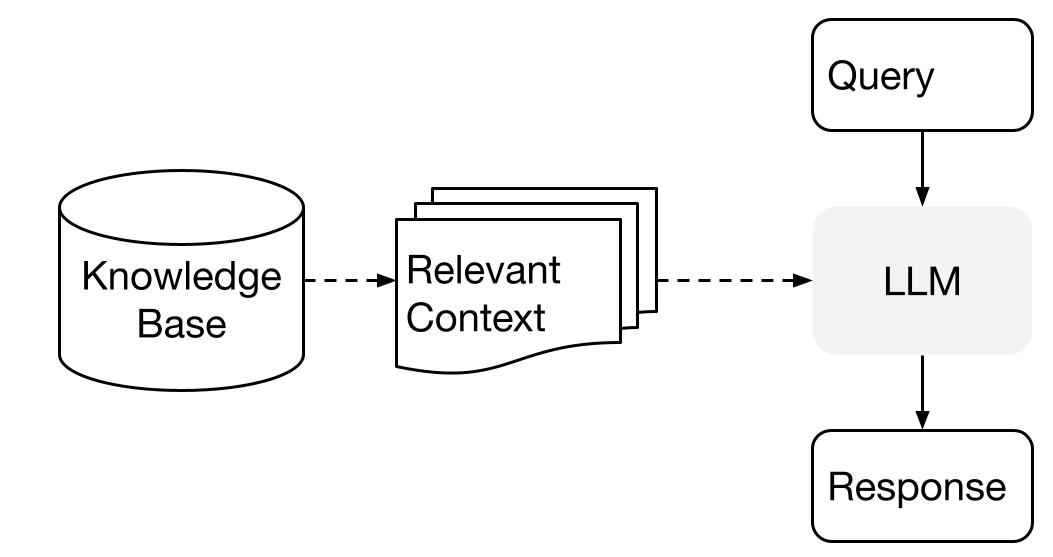
Questo processo è anche conosciuto come Retrieval Augmented Generation (RAG).
LlamaIndex.TS fornisce il toolkit essenziale per rendere entrambe le fasi estremamente facili.
Esploriamo ogni fase nel dettaglio.
Fase di indicizzazione
LlamaIndex.TS ti aiuta a preparare la base di conoscenza con una serie di connettori dati e indici.

Data Loaders:
Un connettore dati (ad esempio, Reader) acquisisce dati da diverse fonti e formati dati in una semplice rappresentazione Document (testo e metadati semplici).
Documenti / Nodi: Un Document è un contenitore generico per qualsiasi fonte di dati - ad esempio, un PDF, un output di un'API o dati recuperati da un database. Un Node è l'unità atomica di dati in LlamaIndex e rappresenta un "chunk" di un Document di origine. È una rappresentazione completa che include metadati e relazioni (con altri nodi) per consentire operazioni di recupero accurate ed espressive.
Indici dei dati: Una volta che hai acquisito i tuoi dati, LlamaIndex ti aiuta a indicizzare i dati in un formato facilmente recuperabile.
Sotto il cofano, LlamaIndex analizza i documenti grezzi in rappresentazioni intermedie, calcola gli embedding vettoriali e memorizza i tuoi dati in memoria o su disco.
"
Fase di interrogazione
Nella fase di interrogazione, la pipeline di interrogazione recupera il contesto più rilevante dato una query dell'utente, e lo passa al LLM (insieme alla query) per sintetizzare una risposta.
Ciò fornisce al LLM una conoscenza aggiornata che non è presente nei suoi dati di addestramento originali, (riducendo anche l'allucinazione).
La sfida principale nella fase di interrogazione è il recupero, l'orchestrazione e il ragionamento su (potenzialmente molte) basi di conoscenza.
LlamaIndex fornisce moduli componibili che ti aiutano a costruire e integrare pipeline RAG per Q&A (motore di interrogazione), chatbot (motore di chat) o come parte di un agente.
Questi blocchi di costruzione possono essere personalizzati per riflettere le preferenze di ranking, nonché composti per ragionare su più basi di conoscenza in modo strutturato.
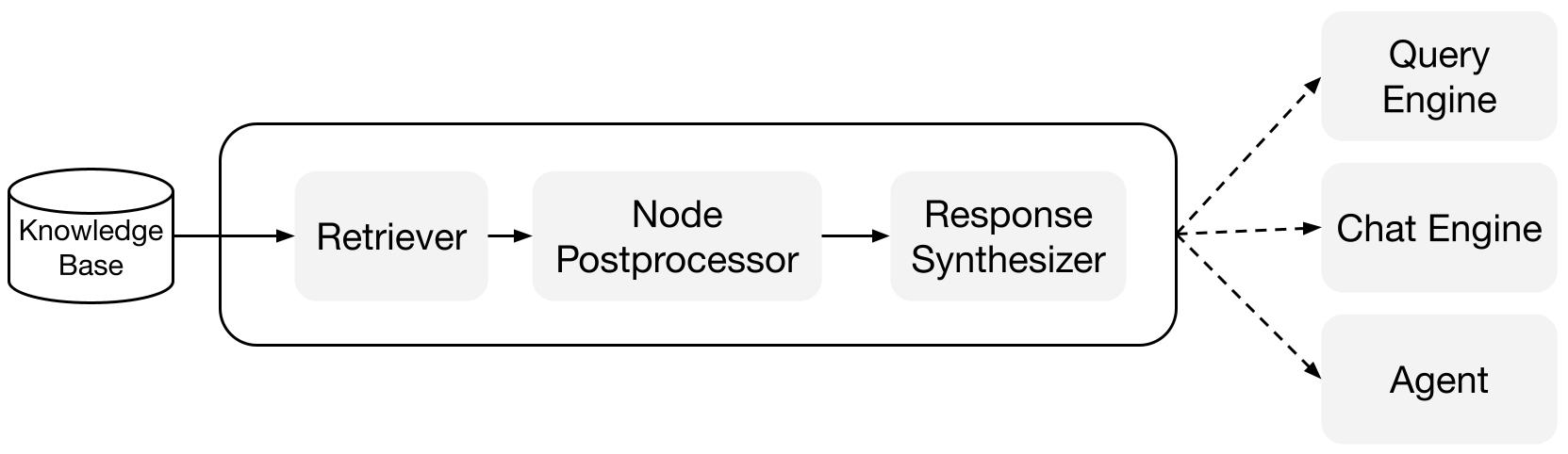
Blocchi di costruzione
Retriever: Un retriever definisce come recuperare efficientemente il contesto rilevante da una base di conoscenza (cioè un indice) quando viene fornita una query. La logica specifica di recupero differisce per diversi indici, il più popolare è il recupero denso su un indice vettoriale.
Response Synthesizers: Un response synthesizer genera una risposta da un LLM, utilizzando una query dell'utente e un insieme di frammenti di testo recuperati.
"
Pipeline
Motori di interrogazione: Un motore di interrogazione è una pipeline end-to-end che ti consente di fare domande sui tuoi dati. Prende in input una query in linguaggio naturale e restituisce una risposta, insieme al contesto di riferimento recuperato e passato al LLM.
Motori di chat: Un motore di chat è una pipeline end-to-end per avere una conversazione con i tuoi dati (più scambi di domande e risposte anziché una singola domanda e risposta).
"